Как автоматизировать репликацию и отказоустойчивость PostgreSQL 12 с помощью repmgr - часть 1
repmgr - это набор инструментов с открытым исходным кодом от 2ndQuadrant, ведущего специалиста в технологиях и сервисах, связанных с PostgreSQL. Продукт используется для автоматизации, улучшения и управления потоковой репликацией PostgreSQL.
Потоковая репликация в PostgreSQL существует с версии 9.0. Нативная настройка и управление потоковой репликацией включает в себя ряд ручных шагов, которые включают в себя:
В этой серии из двух частей мы увидим, как repmgr и его демон repmgrd могут автоматизировать высокую доступность и отказоустойчивость кластера PostgreSQL 12 с тремя узлами.
В первой части мы настроим репликацию с использованием repmgr и зарегистрируем все узлы. Мы увидим, как проверить состояние всего кластера с помощью простой команды.
Во второй части мы смоделируем отказ основного узла и увидим, как демон repmgr может автоматически определять сбой и переводить один из резеврных узлов в основной. Мы также увидим, как repmgrd может начать новую репликацию с основного на резервный узел.
Также будет "узел-свидетель" с именем "PG-Node-Witness", работающий в той же сети, что и основной узел. Но он не будет частью основного кластера репликации. Как автономный узел, он будет иметь минимальные изменения конфигурации. Роль следящего сервера состоит в том, чтобы помочь демонам repmgr на резервных узлах достичь кворума, когда первичный сервер становится недоступным. Чтобы сделать это возможным, узел-свидетель будет размещать небольшую базу данных. Эта база данных будет содержать копию основных метаданных repmgr и необходима для работы в качестве свидетеля.
На рисунке ниже показана архитектура кластера:
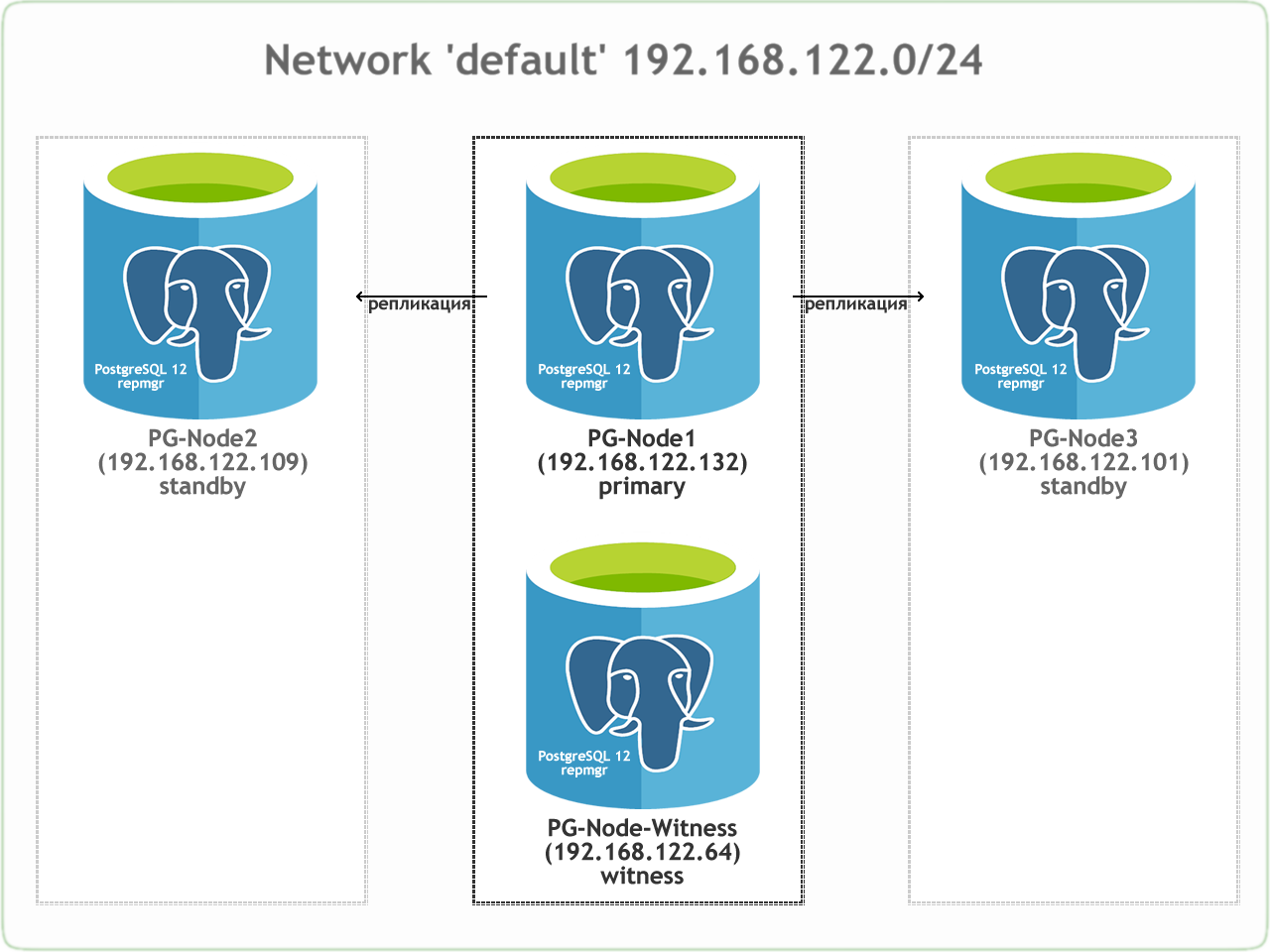
На протяжении всего этого поста мы будем ссылаться на каждый из этих узлов, поэтому вот таблица, показывающая их детали:
Поскольку PG-Node2 и PG-Node3 являются резервными узлами, мы оставляем их и запускаем initdb только на основном (PG-Node1) и следящем (PG-Node-Witness) узлах:
После внесения изменений запускаем и включаем службу PostgreSQL 12 на PG-Node1 и на PG-Node-Witness.
После этого установим пакет repmgr:
Далее выполняем следующие команды только на primary узле PG-Node1. Обратите внимание, что необходимо переключиться на пользователя postgres из командной строки перед выполнением этих команд.
Первая команда создает пользователя repmgr:
Вторая команда создает базу данных repmgr и делает пользователя repmgr её владельцем:
И наконец, изменим путь поиска по умолчанию для пользователя repmgr:
Этот параметр загрузит библиотеки repmgr при запуске PostgreSQL. По умолчанию любые конфигурационные файлы PostgreSQL, присутствующие в каталоге data, будут скопированы на standby узлы (PG-Node2 и PG-Node3), поэтому любые параметры, настроенные для PG-Node1, будут также скопированы на PG-NodeX.
Шаг 6: Настройка repmgr на primary и standby узлах
Для PostgreSQL 12 по умолчанию файл конфигурации repmgr находится в /etc/repmgr/12/ и называется repmgr.conf. На primary и standby узлы добавим эти строки:
На primary (PG-Node1):
На standby 1 (PG-Node2):
На standby 2 (PG-Node3):
Это минимальные параметры, которые нужно добавить для настройки репликации с помощью repmgr. Обратите внимание на то, как назначается уникальный идентификатор узла для каждого сервера и присваивается ему имя. Имя может быть произвольным, но в этом случае сохраняем его как имя хоста. Также указываем строку подключения для каждого узла и указываем местоположение каталога данных PostgreSQL.
После этого перезапустим PostgreSQL:
Чтобы проверить, могут ли standby узлы подключаться к primary узлу, запустим следующую команду из PG-Node2 и PG-Node3:
В нашем тестовом примере подключение работает, когда мы видим приглашение PostgreSQL primary узла в базе данных repmgr:
Вывод выглядит так:
Теперь мы можем проверить состояние нашего кластера:
Как и ожидалось, наш кластер имеет только один узел - primary:
Если вывод похож на следующий, значит клонирование было успешным:
Если оба резервных узла отображают "all prerequisites for "standby clone" are met", значит мы можем продолжить операцию клонирования:
Успешная операция клонирования показывает сообщения вроде этого:
Затем мы запускаем следующую команду на каждом standby узле под пользователем postgres, чтобы зарегистрировать его в repmgr:
Успешная регистрация покажет сообщения:
Или можно запустить команду repmgr с любого из узлов под пользователем postgres:
Результат показывает, что PG-Node1 как primary и два других как standby:
Кроме того, регистрация узла с помощью repmgr позволяет нам видеть его состояние из любого узла.
Настройка потоковой репликации - это только половина работы. Чтобы получить действительно автоматизированное аварийное переключение, надо настроить дополнительные параметры в файле repmgr.conf и использовать демон repmgr.
Об этом во второй части статьи.
Как автоматизировать репликацию и отказоустойчивость PostgreSQL 12 с помощью repmgr - часть 2
Потоковая репликация в PostgreSQL существует с версии 9.0. Нативная настройка и управление потоковой репликацией включает в себя ряд ручных шагов, которые включают в себя:
- Настройка параметров репликации как на основном, так и на каждом резервном узле;
- Резервное копирование данных основного узла с помощью pg_basebackup с каждого резервного узла и его восстановление;
- Перезапуск резервного узла(ов).
- Проверка состояния репликации с помощью операторов SQL;
- Содействие резервному узлу, когда необходимо переключение или когда основной недоступен;
- Отключение или остановка основного узела;
- Пересоздание репликации с нового read/write узла на существующие или новые резервные узлы.
В этой серии из двух частей мы увидим, как repmgr и его демон repmgrd могут автоматизировать высокую доступность и отказоустойчивость кластера PostgreSQL 12 с тремя узлами.
В первой части мы настроим репликацию с использованием repmgr и зарегистрируем все узлы. Мы увидим, как проверить состояние всего кластера с помощью простой команды.
Во второй части мы смоделируем отказ основного узла и увидим, как демон repmgr может автоматически определять сбой и переводить один из резеврных узлов в основной. Мы также увидим, как repmgrd может начать новую репликацию с основного на резервный узел.
Окружение
Мы настроим наш кластер PostgreSQL на виртуальных машинах KVM с настройками по умолчанию. Каждый узел это: 1 ядро, 20 Гб, сеть default и ОС CentOS 8. Все узлы находятся в одной сети "default" и будут работать с PostgreSQL 12. Основной узел будет реплицироваться на два резервных узла, причем все три узла также будут работать с repmgr.Также будет "узел-свидетель" с именем "PG-Node-Witness", работающий в той же сети, что и основной узел. Но он не будет частью основного кластера репликации. Как автономный узел, он будет иметь минимальные изменения конфигурации. Роль следящего сервера состоит в том, чтобы помочь демонам repmgr на резервных узлах достичь кворума, когда первичный сервер становится недоступным. Чтобы сделать это возможным, узел-свидетель будет размещать небольшую базу данных. Эта база данных будет содержать копию основных метаданных repmgr и необходима для работы в качестве свидетеля.
На рисунке ниже показана архитектура кластера:
На протяжении всего этого поста мы будем ссылаться на каждый из этих узлов, поэтому вот таблица, показывающая их детали:
| Узел | IP адрес | Роль | Приложения |
| PG-Node1 | 192.168.122.132 | Primary | PostgreSQL 12 и repmgr |
| PG-Node2 | 192.168.122.109 | Standby 1 | PostgreSQL 12 и repmgr |
| PG-Node3 | 192.168.122.101 | Standby 2 | PostgreSQL 12 и repmgr |
| PG-Node-Witness | 192.168.122.64 | Witness | PostgreSQL 12 и repmgr |
Шаг 1: Установка PostgreSQL 12 на все узлы
Все наши узлы (виртуальные машины) работают под управлением CentOS 8. На каждом узле мы выполняем следующие команды. Первая команда добавляет репозиторий PostgreSQL Global Development Group (PGDG), вторая отключает встроенный модуль RHEL PostgreSQL и, наконец, третья устанавливает PostgreSQL 12 из репозитория PGDG.# dnf -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# dnf -qy module disable postgresql
# dnf install postgresql12-server postgresql12-contribПоскольку PG-Node2 и PG-Node3 являются резервными узлами, мы оставляем их и запускаем initdb только на основном (PG-Node1) и следящем (PG-Node-Witness) узлах:
# /usr/pgsql-12/bin/postgresql-12-setup initdbШаг 2: Настройка PostgreSQL на PG-Node-Witness и PG-Node1
На PG-Node-Witness вносим следующие изменения в файл postgresql.conf:listen_addresses = '*'Шаги, описанные здесь, только для демонстрационных целей. В этом примере - использование прослушивания всех адресов listen_address = '*' вместе с механизмом безопасности pg_hba "trust" (показано ниже) создает угрозу безопасности и НЕ должно использоваться в производственных сценариях. В производственной системе все узлы должны находиться в одной или нескольких частных подсетях, доступ к которым можно получить только через частные IP-адреса
На PG-Node1 добавляем эти строки в конец файла postgresql.conf:listen_addresses = '*'
max_wal_senders = 10
max_replication_slots = 10
wal_level = 'replica'
hot_standby = on
archive_mode = on
archive_command = '/bin/true'После внесения изменений запускаем и включаем службу PostgreSQL 12 на PG-Node1 и на PG-Node-Witness.
# systemctl start postgresql-12.service
# systemctl enable postgresql-12.serviceШаг 3: Установка repmgr на primary и standby узлах
Для CentOS 8 необходимо установить репозиторий repmgr на primary узле (PG-Node1) и на обоих standby узлах (PG-Node2 и PG-Node3):# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpmПосле этого установим пакет repmgr:
# yum install repmgr12 –yШаг 4: Создание пользователя и базы данных с именем repmgr на PG-Node1
repmgr использует свою собственную базу данных для хранения своих метаданных. Также рекомендуется использовать специальную учетную запись пользователя PostgreSQL для этого приложения. Имя пользователя и имя базы данных могут быть любыми, но для простоты назовем их обоих “repmgr”. Кроме того, пользователь будет создан как суперпользователь PostgreSQL. Это рекомендуется 2ndQuadrant, так как некоторые операции repmgr требуют повышенных привилегий.Далее выполняем следующие команды только на primary узле PG-Node1. Обратите внимание, что необходимо переключиться на пользователя postgres из командной строки перед выполнением этих команд.
Первая команда создает пользователя repmgr:
[postgres@PG-Node1 ~]$ createuser --superuser repmgrВторая команда создает базу данных repmgr и делает пользователя repmgr её владельцем:
[postgres@PG-Node1 ~]$ createdb --owner=repmgr repmgrИ наконец, изменим путь поиска по умолчанию для пользователя repmgr:
[postgres@PG-Node1 ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"Шаг 5: Добавление параметра в конфигурационный файл PostgreSQL на PG-Node1
Создав базу данных и пользователя, на primary узле добавим следующую строку в файл postgresql.conf:shared_preload_libraries = 'repmgr'Этот параметр загрузит библиотеки repmgr при запуске PostgreSQL. По умолчанию любые конфигурационные файлы PostgreSQL, присутствующие в каталоге data, будут скопированы на standby узлы (PG-Node2 и PG-Node3), поэтому любые параметры, настроенные для PG-Node1, будут также скопированы на PG-NodeX.
Шаг 6: Настройка repmgr на primary и standby узлах
Для PostgreSQL 12 по умолчанию файл конфигурации repmgr находится в /etc/repmgr/12/ и называется repmgr.conf. На primary и standby узлы добавим эти строки:
На primary (PG-Node1):
node_id=1
node_name='PG-Node1'
conninfo='host=192.168.122.132 user=repmgr dbname=repmgr
connect_timeout=2'
data_directory='/var/lib/pgsql/12/data'На standby 1 (PG-Node2):
node_id=2
node_name='PG-Node2'
conninfo='host=192.168.122.109 user=repmgr dbname=repmgr
connect_timeout=2'
data_directory='/var/lib/pgsql/12/data'На standby 2 (PG-Node3):
node_id=3
node_name='PG-Node3'
conninfo='host=192.168.122.101 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/var/lib/pgsql/12/data'Это минимальные параметры, которые нужно добавить для настройки репликации с помощью repmgr. Обратите внимание на то, как назначается уникальный идентификатор узла для каждого сервера и присваивается ему имя. Имя может быть произвольным, но в этом случае сохраняем его как имя хоста. Также указываем строку подключения для каждого узла и указываем местоположение каталога данных PostgreSQL.
Шаг 7: Настройка pg_hba.conf на primary узле
Далее добавим следующие строки в файл pg_hba.conf на PG-Node1. Как мы увидим позже, файл pg_hba.conf с primary узла будет скопирован на два standby узла, когда repmgr настроит репликацию. Обратите внимание на использование диапазона CIDR кластера вместо указания отдельных IP.local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.122.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.122.0/24 trustПосле этого перезапустим PostgreSQL:
# systemctl restart postgresql-12.serviceЧтобы проверить, могут ли standby узлы подключаться к primary узлу, запустим следующую команду из PG-Node2 и PG-Node3:
# psql 'host=192.168.122.132 user=repmgr dbname=repmgr connect_timeout=2'В нашем тестовом примере подключение работает, когда мы видим приглашение PostgreSQL primary узла в базе данных repmgr:
# repmgr>Шаг 8: Регистрация primary узла в repmgr
На PG-Node1 под пользователем postgres запустим команду. Этим мы зарегистрируем инстанс PostgreSQL как primary с помощью repmgr. Эта команда так же установит расширение repmgr и добавит метаданные о primary узле в базу данных repmgr.[postgres@PG-Node1 ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf primary registerВывод выглядит так:
INFO: connecting to primary database...
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (ID: 1) registeredТеперь мы можем проверить состояние нашего кластера:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster showКак и ожидалось, наш кластер имеет только один узел - primary:
ID | Name | Role | Status | Upstream | Connection string
----+----------+---------+-----------+----------+--------------------
1 | PG-Node1 | primary | * running | | host=PG-Node1 dbname=repmgr user=repmgr connect_timeout=2Шаг 9: Клонирование standby узлов
Далее мы выполним следующую команду на обоих standby узлах (PG-Node2 и PG-Node3) под пользователем postgres в режиме dry-run, чтобы убедиться, что всё сделали правильно перед фактическим клонированием данных с primary узла:[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -h 192.168.122.132 -U repmgr -d repmgr -f /etc/repmgr/12/repmgr.conf standby clone --dry-runЕсли вывод похож на следующий, значит клонирование было успешным:
NOTICE: using provided configuration file "/etc/repmgr.conf"
destination directory "/var/lib/pgsql/12/data" provided
INFO: connecting to source node
NOTICE: checking for available walsenders on source node (2 required)
INFO: sufficient walsenders available on source node (2 required)
NOTICE: standby will attach to upstream node 1
HINT: consider using the -c/--fast-checkpoint option
INFO: all prerequisites for "standby clone" are metЕсли оба резервных узла отображают "all prerequisites for "standby clone" are met", значит мы можем продолжить операцию клонирования:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -h 192.168.122.132 -U repmgr -d repmgr -f /etc/repmgr/12/repmgr.conf standby cloneУспешная операция клонирования показывает сообщения вроде этого:
NOTICE: destination directory "/var/lib/pgsql/12/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=192.168.122.132 user=repmgr dbname=repmgr
DETAIL: current installation size is 66 MB
NOTICE: checking for available walsenders on the source node (2 required)
NOTICE: checking replication connections can be made to the source server (2 required)
INFO: checking and correcting permissions on existing directory "/var/lib/pgsql/12/data"
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
INFO: executing:
/usr/pgsql-12/bin/pg_basebackup -l "repmgr base backup" -D /var/lib/pgsql/12/data -h 192.168.122.132 -p 5432 -U repmgr -X stream
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /var/lib/pgsql/12/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Шаг 10: Регистрация standby узлов с помощью repmgr
На этом этапе PostgreSQL не работает ни на одном из standby узлов, хотя у обоих есть каталог данных Postgres, скопированный с primary (включая любые файлы конфигурации PostgreSQL, присутствующие в каталоге данных primary узла). Мы запускаем и включаем postgresql на обоих узлах:# systemctl start postgresql-12.service
# systemctl enable postgresql-12.serviceЗатем мы запускаем следующую команду на каждом standby узле под пользователем postgres, чтобы зарегистрировать его в repmgr:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf standby registerУспешная регистрация покажет сообщения:
INFO: connecting to local node "PG-NodeX" (ID: 3)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID 1)
INFO: standby registration complete
NOTICE: standby node "PG-NodeX" (ID: X) successfully registeredПоследний шаг: проверка статуса репликации
Теперь все на месте: PG-Node1 реплицируется как на PG-Node2, так и на PG-Node3. Чтобы проверить это, мы можем запустить команду на любом узле под пользователем postgres:SELECT * FROM pg_stat_replication;Или можно запустить команду repmgr с любого из узлов под пользователем postgres:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compactРезультат показывает, что PG-Node1 как primary и два других как standby:

Подведём итоги
Это было очень быстрое введение в repmgr, который предоставляет простой в использовании интерфейс поверх технологии, уже встроенной в PostgreSQL для настройки репликации. С помощью repmgr мы можем довольно легко настроить столько резервных узлов, сколько необходимо (в пределах ограничений max_wal_senders), что в противном случае включало бы несколько сложных и многошаговых процессов установки / клонирования. Все, что нам нужно, это установить и настроить repmgr на каждом узле, а затем запустить команду "repmgr standby clone".Кроме того, регистрация узла с помощью repmgr позволяет нам видеть его состояние из любого узла.
Настройка потоковой репликации - это только половина работы. Чтобы получить действительно автоматизированное аварийное переключение, надо настроить дополнительные параметры в файле repmgr.conf и использовать демон repmgr.
Об этом во второй части статьи.
Как автоматизировать репликацию и отказоустойчивость PostgreSQL 12 с помощью repmgr - часть 2

Комментариев 2