top, iostat, vmstat и pidstat. Мониторим Linux
Важная часть обязанностей системного администратора состоит в том, чтобы обеспечить работоспособность сервера. В Linux для этой цели доступен широкий набор инструментов. В этой статье дается обзор некоторых наиболее важных инструментов, которые можно использовать для мониторинга и представления отчетов о производительности.
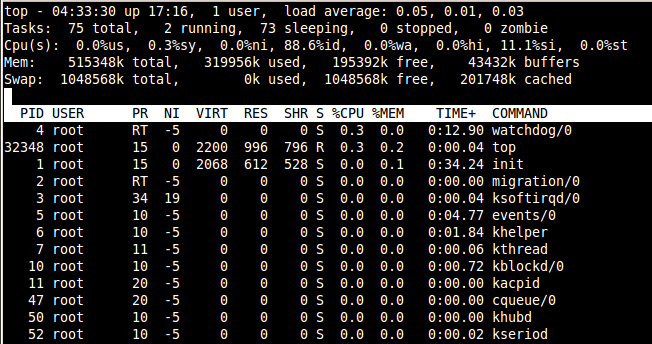
Чтобы понять среднюю нагрузку, вам нужно знать, что каждый процесс, который нужно обслуживать, попадает в очередь выполнения, прежде чем шедулер ядра сможет выделить его для запуска на ядре ЦП. Среднее значение загрузки показывает среднее число процессов, которые ожидают обработки в любой данный момент.
Поскольку любое ядро ЦП может обрабатывать только один процесс, средняя нагрузка всегда должна быть связана с количеством ядер ЦП на сервере. В качестве приблизительного ориентира, число, указанное в качестве средней нагрузки, не должно быть намного выше, чем общее количество ядер ЦП. Таким образом, если ваш сервер имеет четыре ядра, четыре процесса могут быть обработаны одновременно, и нагрузка процессора не должна быть выше четырех.. Если это так, вам нужно выяснить, почему это так, и убедиться, что ваш сервер не перегружен.
Глядя на среднюю нагрузку, вы можете подумать, что 7% времени ожидания (wa) не так уж и плохо, но на вашем 16-ядерном сервере вполне может оказаться, что один ЦП занят на 100% в ожидании ввода / вывода, что означает, что у вас есть процесс, который вызывает проблемы. Таблица 1 суммирует различные значения в строке загрузки ЦП.
Таблица 1
Таблица 3 суммирует статистику использования оперативной памяти:
Чтобы понять параметры использования памяти, вы должны знать, что ядро Linux использует физическую память максимально эффективно. Обычно часть оперативной памяти используется для загрузки программ. Если памяти достаточно, другая ее часть будет использоваться для кэширования недавно прочитанных файлов. Это та часть, которая отображается как cached Mem в top.
Благодаря этой функции кэширования памяти система может работать намного быстрее. То, что отображается в top как cache, ускоряет доступ к диску. Если часто используемые файлы хранятся в кеше, их не нужно извлекать с диска в следующий раз, когда они понадобятся, что повышает общую производительность вашего сервера.
На сервере Linux, который был запущен в течение длительного периода, вы заметите, что доступен только небольшой процент свободной памяти и относительно большой объем памяти находится в кеше. Как уже упоминалось, это хорошо для производительности, и это не оказывает никакого негативного влияния на производительность вашего сервера. Когда больше памяти должно быть выделено, ядро может легко сбрасывать кэши и делать память в кэше доступной для загрузки программ.
Однако вы должны заметить, что для кэширования файлов всегда должно быть достаточно памяти. Файлы, которые не находятся в кеше, необходимо извлекать с диска, а извлечение файлов с диска на самом деле намного медленнее и отрицательно скажется на общей производительности вашего сервера. В качестве приблизительного ориентира, примерно 25% памяти должно быть доступно как свободная память или использоваться кешем. (Обратите внимание, что есть исключения из этой рекомендации; она зависит от того, что делает ваш сервер!)
Буферная память сравнима с кеш-памятью. Буферы используются для неструктурированных данных, таких как таблицы файловой системы, таблицы inode и другие. Как правило, количество используемых буферов не должно быть таким же большим, как объем используемого кэша, но есть исключения из этого общего руководства. Попробуйте, например, команду find /> /dev/null и посмотрите, как она влияет на использование буферов. Поскольку многие структуры метаданных файловой системы должны быть доступны, они будут загружены в память и увеличат объем выделяемого буферного кэша.
Листинг 1
Если возникает нехватка памяти, ядро Linux может делать два действия:
■ Начать удалять кеш: это действие сразу делает доступным больше памяти, но в следующий раз, когда файлы, находящиеся в кеше, будут запрошены, их нужно будет прочитать с диска и снова поместить в кеш. Если ядро удаляет только неактивную (файловую) память, это не имеет большого значения, потому что это страницы памяти, которые так или иначе не использовались в последнее время.
■ Использовать swap: вся неактивная память является отличным кандидатом для перехода на своп. Эти страницы памяти используются приложениями, но не использовались в последнее время.
Обратите внимание, что утилита free тоже дает обзор текущей статистики использования памяти. В листинге 2 показаны выходные данные этой команды.
Листинг 2
Утилита top
Утилита top является одним из лучших инструментов для мониторинга данных о производительности. Он предоставляет обзор в реальном времени того, что происходит на сервере, и имеет много опций для настройки того, какие конкретные данные о производительности следует отслеживать.Понимание средней нагрузки
Первым параметром, который нужно учитывать при анализе производительности через top, является среднее значение нагрузки в правом верхнем углу верхнего вывода (смотрите скриншот наверху).Чтобы понять среднюю нагрузку, вам нужно знать, что каждый процесс, который нужно обслуживать, попадает в очередь выполнения, прежде чем шедулер ядра сможет выделить его для запуска на ядре ЦП. Среднее значение загрузки показывает среднее число процессов, которые ожидают обработки в любой данный момент.
Поскольку любое ядро ЦП может обрабатывать только один процесс, средняя нагрузка всегда должна быть связана с количеством ядер ЦП на сервере. В качестве приблизительного ориентира, число, указанное в качестве средней нагрузки, не должно быть намного выше, чем общее количество ядер ЦП. Таким образом, если ваш сервер имеет четыре ядра, четыре процесса могут быть обработаны одновременно, и нагрузка процессора не должна быть выше четырех.. Если это так, вам нужно выяснить, почему это так, и убедиться, что ваш сервер не перегружен.
Данные о производительности процессора
Второй показатель производительности находится в третьей строке сверху, он показывает процент использования процессора. По умолчанию эта строка суммирует данные о производительности для всех процессоров в системе. Если вы нажмете 1, вы увидите одну строку для каждого ядра процессора. На современных серверах, где часто используются несколько ядер ЦП, важно следить за использованием ЦП.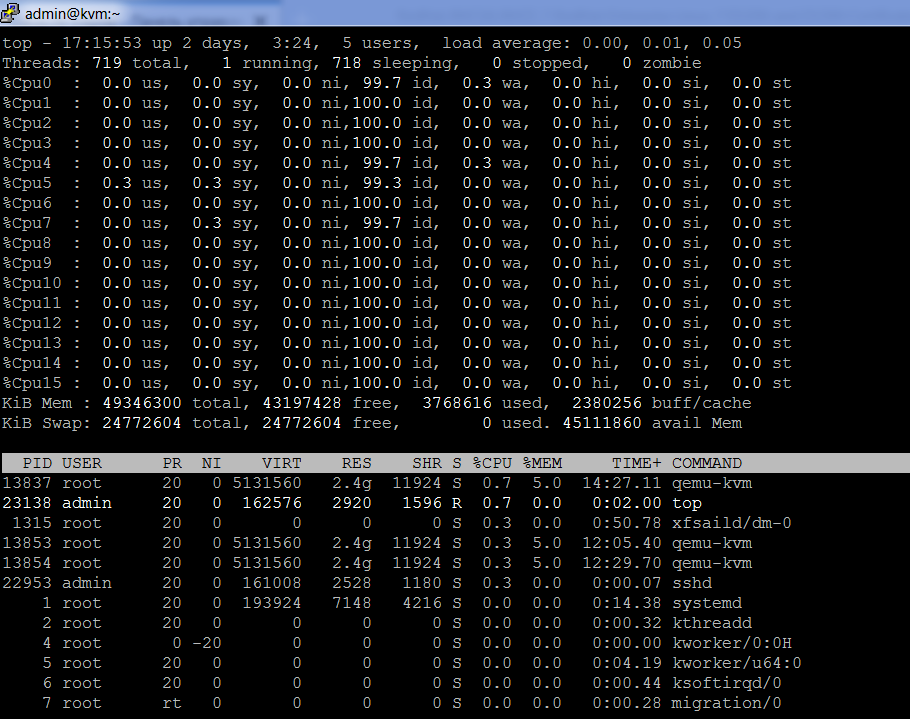
Глядя на среднюю нагрузку, вы можете подумать, что 7% времени ожидания (wa) не так уж и плохо, но на вашем 16-ядерном сервере вполне может оказаться, что один ЦП занят на 100% в ожидании ввода / вывода, что означает, что у вас есть процесс, который вызывает проблемы. Таблица 1 суммирует различные значения в строке загрузки ЦП.
Таблица 1
| Индикатор | Объяснение |
| us | Процент времени, затрачиваемого процессором на обработку процессов в пользовательском режиме. Обычно это процессы, которые были запущены без привилегий root и не взаимодействуют напрямую с ядром Linux. |
| sy | Процент времени, в течение которого процессор работает в режиме ядра. Это глобальное время, которое тратится на обработку системных вызовов и доступ к драйверам. |
| ni | Процент времени, в течение которого сервер обрабатывает процессы, значение которых было изменено. |
| id | Процент времени, в течение которого процессор проводит в режиме ожидания. Это время, когда процессор доступен, не отнимая время у других процессов. |
| wa | Время, которое процессор тратит на ожидание бесперебойного ввода-вывода, такого как запросы на диски, жестко смонтированные NFS и ленточные устройства. Высокое значение в этом параметре указывает на медленную работу стораджа и может нуждаться в дальнейшей оптимизации, которая обычно применяется к каналу стораджа. |
| hi | Время, которое процессор тратит на обработку аппаратных прерываний. Высокое значение может указывать на неисправное оборудование. |
| si | Время, которое процессор тратит на обработку программных прерываний. |
| st | Процент украденного времени. Этот параметр отображается в среде виртуализации, где виртуальные машины «крадут» процессорное время у гипервизора. |
Использование памяти
Другой важный показатель производительности, который показывает top, - это использование памяти. Отображается информация об использовании оперативной памяти и использовании файла подкачки. Читая эту статистику, вы можете убедиться, что на вашем сервере достаточно оперативной памяти для выполнения задач, которые он должен выполнить.Таблица 3 суммирует статистику использования оперативной памяти:
Индикатор | Объяснение |
| KiB Mem | Общий объем физической памяти в KiB (1 KiB = 1024 байта). |
| used | Общий объем оперативной памяти, которая используется для чего-угодно. |
| free | Общий объем оперативной памяти, который не используется ни для чего. |
| buffers | Общий объем используемой памяти, используемой для хранения неструктурированных данных. |
| cached Mem | Общий объем памяти, который используется для кэширования файлов, которые были недавно извлечены с диска. |
Чтобы понять параметры использования памяти, вы должны знать, что ядро Linux использует физическую память максимально эффективно. Обычно часть оперативной памяти используется для загрузки программ. Если памяти достаточно, другая ее часть будет использоваться для кэширования недавно прочитанных файлов. Это та часть, которая отображается как cached Mem в top.
Благодаря этой функции кэширования памяти система может работать намного быстрее. То, что отображается в top как cache, ускоряет доступ к диску. Если часто используемые файлы хранятся в кеше, их не нужно извлекать с диска в следующий раз, когда они понадобятся, что повышает общую производительность вашего сервера.
На сервере Linux, который был запущен в течение длительного периода, вы заметите, что доступен только небольшой процент свободной памяти и относительно большой объем памяти находится в кеше. Как уже упоминалось, это хорошо для производительности, и это не оказывает никакого негативного влияния на производительность вашего сервера. Когда больше памяти должно быть выделено, ядро может легко сбрасывать кэши и делать память в кэше доступной для загрузки программ.
Однако вы должны заметить, что для кэширования файлов всегда должно быть достаточно памяти. Файлы, которые не находятся в кеше, необходимо извлекать с диска, а извлечение файлов с диска на самом деле намного медленнее и отрицательно скажется на общей производительности вашего сервера. В качестве приблизительного ориентира, примерно 25% памяти должно быть доступно как свободная память или использоваться кешем. (Обратите внимание, что есть исключения из этой рекомендации; она зависит от того, что делает ваш сервер!)
Буферная память сравнима с кеш-памятью. Буферы используются для неструктурированных данных, таких как таблицы файловой системы, таблицы inode и другие. Как правило, количество используемых буферов не должно быть таким же большим, как объем используемого кэша, но есть исключения из этого общего руководства. Попробуйте, например, команду find /> /dev/null и посмотрите, как она влияет на использование буферов. Поскольку многие структуры метаданных файловой системы должны быть доступны, они будут загружены в память и увеличат объем выделяемого буферного кэша.
Swap
Во многих системах Linux вы увидите память, доступную как swap. Swap эмулируется оперативной памятью на диске. Поскольку ядро Linux использует swap очень эффективно, нет проблем, если swap активно используется. При распределении файла подкачки ядро Linux делает разницу между активной и неактивной памятью. Это различие сделано для анонимных страниц памяти (обычно это память приложения) и файловой памяти (память в буферах и кеше). Вы можете посмотреть текущую статистику использования памяти в /proc/meminfo (см. Листинг 1).Листинг 1
Active: 450832 kB
Inactive: 259008 kB
Active(anon): 358196 kB
Inactive(anon): 173332 kB
Active(file): 92636 kB
Inactive(file): 85676 kBЕсли возникает нехватка памяти, ядро Linux может делать два действия:
■ Начать удалять кеш: это действие сразу делает доступным больше памяти, но в следующий раз, когда файлы, находящиеся в кеше, будут запрошены, их нужно будет прочитать с диска и снова поместить в кеш. Если ядро удаляет только неактивную (файловую) память, это не имеет большого значения, потому что это страницы памяти, которые так или иначе не использовались в последнее время.
■ Использовать swap: вся неактивная память является отличным кандидатом для перехода на своп. Эти страницы памяти используются приложениями, но не использовались в последнее время.
Обратите внимание, что утилита free тоже дает обзор текущей статистики использования памяти. В листинге 2 показаны выходные данные этой команды.
Листинг 2
[admin@kvm ~]$ free -m
total used free shared buff/cache available
Mem: 48189 3680 42183 69 2325 44054
Swap: 24191 0 24191
[admin@kvm ~]$[/code]
В своем выводе команда free -m дает общее представление об общем объеме памяти, объеме используемой памяти и объеме доступной памяти. Обратите внимание, что общая память отображается как использованная + свободная + буферная / кэш-память.
Когда команда free была обновлена в RHEL 7.1/CentOS 7.1, был добавлен параметр available. Этот параметр показывает объем памяти, который доступен как свободная память плюс неактивная файловая память (которая относится к кэшированным файлам, которые не использовались в последнее время). Вторая строка команды free -m показывает информацию об использовании свопа.
Если требуются дополнительные сведения о структуре пространства подкачки, вы можете использовать команду swapon -s. Как показано в листинге 3, эта команда показывает, какие устройства подкачки в настоящее время выделены как файлы подкачки.
Вы можете увидеть, что пространство подкачки в системе, где использовалась эта команда, состоит из dm-0 и dm-4, которые являются LVM и которые с помощью команды swapon -s ошибочно определяются как разделы.
[admin@kvm ~]$ swapon -s
Filename Type Size Used Priority
/dev/dm-0 partition 524284 0 -1
/dev/dm-4 partition 102396 0 -2
Использование памяти процесса
Утилита top названа так, потому что процессы отсортированы по использованию ресурсов.
Обычно они сортируются по загрузке процессора. Вы можете сортировать и другие параметры производительности, используя клавиши > и <. Если, например, вы хотите отсортировать данные об использовании памяти, нажмите клавишу > один раз и снова нажмите <, чтобы вернуться к сортировке на % CPU. Для каждого процесса, top показывает текущее использование виртуальной памяти, резидентной памяти и разделяемой памяти.
Виртуальная память не является реальной памятью; это набор указателей, которые устанавливают адреса памяти в виртуальном адресном пространстве. Общее доступное виртуальное адресное пространство на 64-разрядной системе занимает 32 ТБ, и единственная цель этого виртуального адресного пространства состоит в том, что каждый процесс при запуске может устанавливать уникально зарезервированные указатели памяти. Объем виртуальной памяти, зарезервированный процессом, указан в верхнем столбце VIRT.
Когда процесс начинает становиться активным, он выделяет резидентную память. Эта память отображается сверху в столбце RES. Резидентная память - это реальная память, которая должна размещаться в оперативной памяти.
Кастомизация утилиты top
Когда вы работаете с top, можно отобразить другие параметры производительности.
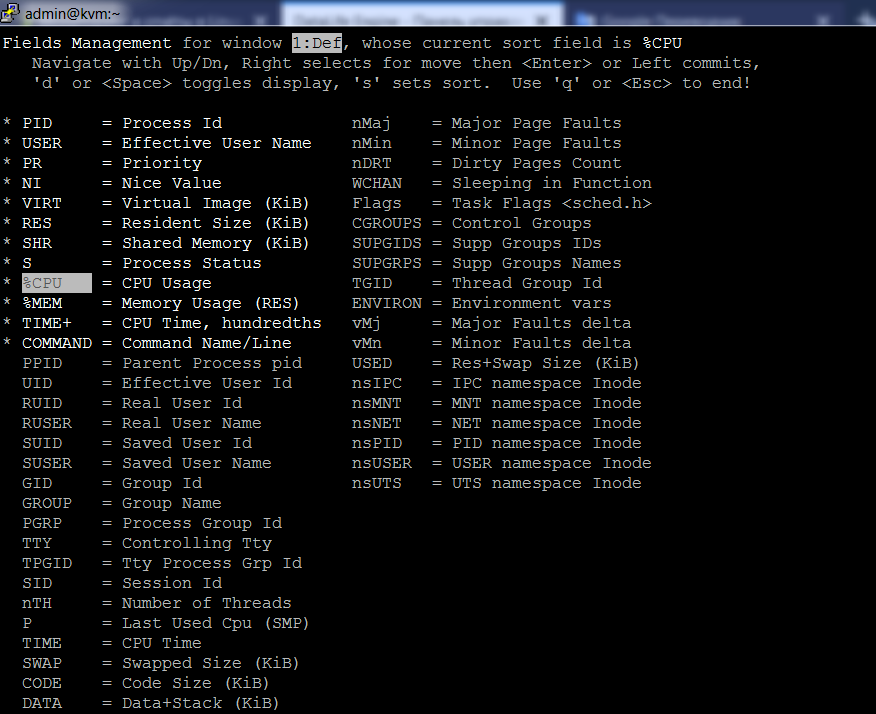
Для просмотра доступных параметров нажмите f. Команда показывает все поля, которые доступны в top. Чтобы добавить определенные поля по умолчанию, перейдите к полю с помощью клавиш со стрелками на клавиатуре и выберите поле, которое вы хотите добавить, с помощью пробела. Сделав свой выбор, нажмите q, чтобы выйти и отобразить интерфейс top с добавленными полями. На скриншоте (кликабельно) ниже показан интерфейс после ввода f.
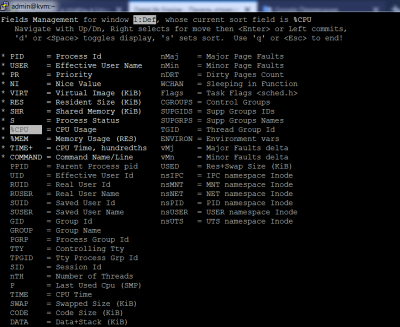
После выбора полей в top, вы можете сделать их постоянными. Для этого нажмите W. Это действие запишет новые настройки в ~/.toprc.
Использование iostat, vmstat и pidstat
Утилита top предлагает общий интерфейс, который показывает многие аспекты производительности Linux, но также доступны некоторые другие утилиты для мониторинга производительности, многие из которых поставляются из пакета sysstat. Таблица 4 описывает эти утилиты. Таблица 4 описывает эти утилиты.
Таблица 4
cifsiostat Показывает статистику производительности для службы обмена файлами CIFS. nfsiostat Показывает статистику производительности для службы обмена файлами NFS. iostat Универсальная утилита, которая показывает статистику производительности I/O. mpstat Используется для отображения информации об использовании процессора в многопроцессорной среде. pidstat Показывает статистику производительности, связанную PID. vmstat Универсальная утилита, которая показывает подробную информацию об использовании памяти.
iostat
Утилита iostat полезна, если вы хотите узнать, какие устройства I/O интенсивно использовались и какое количество операций I/O происходило на этих устройствах. Если вы запустите утилиту без каких-либо аргументов, отобразится результат, который вы можете увидетькак в листинге 4.
Листинг 4[admin@kvm ~]$ iostat
Linux 3.10.0-1062.1.2.el7.x86_64 (kvm) 10/26/2019 _x86_64_ (16 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.12 0.00 0.03 0.05 0.00 99.81
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.77 11.23 5.50 2151695 1054550
dm-0 0.77 11.05 5.43 2116356 1039232
dm-1 0.00 0.01 0.00 2204 0
dm-2 0.01 0.02 0.07 2935 13249
Вывод iostat показывает статистику по каждому устройству. В первом столбце перечислены устройства. Для каждого из этих устройств среднее число транзакций в секунду показано первым. Затем вы увидите, сколько килобайт было прочитано и записано в секунду, и сколько килобайт было записано.
С iostat вы также можете отображать различные параметры производительности. Два интересных параметра: -c, который отображает информацию об использовании процессора, и -d, который показывает информацию об использовании устройства. Вы также можете использовать iostat в continues mode, где используются интервал и счетчик. Например, команда iostat -d /dev/sda 2 10 показывает статистику использования только для устройства /dev/sda, всего 10 циклов опроса с интервалом в 2 секунды.
При использовании iostat в этом режиме вы замечаете, что значения объема данных, которые были прочитаны и записаны, значительно выше в первой строке. Это связано с тем, что первая строка суммирует итоги с момента запуска, а остальные строки суммируют использование в каждом цикле опроса.
vmstat
Утилита vmstat показывает информацию об использовании виртуальной памяти. Как и iostat, вы можете использовать эту утилиту в режиме опроса (polling), используя такие команды, как vmstat 2 5, чтобы показать 5 циклов опроса с интервалом в 2 секунды (см. Листинг 5).
[admin@kvm ~]$ vmstat 2 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 43179952 2120 2379472 0 0 1 0 12 9 0 0 100 0 0
0 0 0 43178688 2120 2379504 0 0 0 0 482 290 0 0 100 0 0
0 0 0 43178696 2120 2379504 0 0 0 0 302 251 0 0 100 0 0
0 0 0 43178836 2120 2379504 0 0 0 0 374 265 0 0 100 0 0
0 0 0 43178836 2120 2379504 0 0 0 0 377 256 0 0 100 0 0
[admin@kvm ~]$
Информация, которая отображается с помощью vmstat, отображается в разных категориях:
procs: предоставляет информацию о количестве процессов, которые были активны в последнем цикле опроса или ожидали устройств I/O.
memory: предоставляет информацию о важных параметрах использования памяти, таких как объем подкачки памяти, свободная память и память, которая в настоящее время выделена для буферов или кеша.
swap: показывает активность свопинга.
io: показывает активность I/O.
system: предоставляет информацию о количестве прерываний и переключений контекста, произошедших в системе.
cpu: выдает информацию об использовании ЦП, например, сколько времени ЦП провел в пространстве пользователя, системном пространстве, цикле простоя, ожидании I/O и работе с украденным временем.
Важной статистикой, которую можно получить из vmstat, является количество блоков, которые были свопированы (swapped in) и освобождены (swapped out). В Linux это неплохо само по себе, если используется своп. Использование свопа плохо только в том случае, если большое количество блоков перемещается из памяти в своп и обратно. На это указывают параметры si и so, которые вы можете видеть под строкой подкачки в выводе vmstat.
Другой распространенный способ использования vmstat - ввод команды vmstat -s. Опция отображает сводку всех параметров, которые важны для производительности в отношении использования памяти (см. Листинг 6).
[admin@kvm ~]$ vmstat -s
49346300 K total memory
3786660 K used memory
4326584 K active memory
1111132 K inactive memory
43177936 K free memory
2120 K buffer memory
2379584 K swap cache
24772604 K total swap
0 K used swap
24772604 K free swap
354085 non-nice user cpu ticks
917 nice user cpu ticks
92627 system cpu ticks
307840631 idle cpu ticks
140589 IO-wait cpu ticks
0 IRQ cpu ticks
4376 softirq cpu ticks
0 stolen cpu ticks
2151735 pages paged in
1060336 pages paged out
0 pages swapped in
0 pages swapped out
81463724 interrupts
70020992 CPU context switches
1571889107 boot time
190333 forks
[admin@kvm ~]$
pidstat
Для мониторинга производительности приложений полезна команда pidstat. Наиболее интересная часть, показанная этой утилитой, касается произошедших переключений контекста. Чтобы включить многозадачность, ядро Linux использует переключатели контекста. Переключение контекста происходит, когда процессор переходит к обработке другой задачи. Переключение контекста относительно дорого с точки зрения производительности, и по этой причине его следует избегать, если это возможно.
Существует два разных типа переключений контекста: произвольные переключатели контекста и принудительные переключатели контекста. Произвольное переключение контекста происходит, когда приложение на данный момент не имеет активных потоков и может перенести управление в другое приложение.
Непроизвольное переключение контекста происходит, когда приложение использует свой временной интервал в планировщике, и планировщик перемещает его, чтобы освободить место для другого потока. Добровольное переключение контекста является лишь частью нормальной работы; по возможности следует избегать принудительных переключений контекста (но это не всегда работает).
Когда потоков требуется больше, чем ядер в системе, ядро распределяет доступность ЦП по потокам, требующим внимания; это способ разделения времени, и при этом произойдут невольные переключения контекста.
Чтобы проверить количество переключений контекста, произошедших в приложении, вы можете использовать команду pidstat. Эта команда также работает с аргументами, которые указывают, сколько циклов опроса должно происходить и как часто они должны происходить. В листинге 7 приведен пример вывода команды pidstat.
[admin@kvm ~]$ pidstat -w -p 13837 2 5
Linux 3.10.0-1062.1.2.el7.x86_64 (kvm) 10/26/2019 _x86_64_ (16 CPU)
07:35:36 PM UID PID cswch/s nvcswch/s Command
07:35:38 PM 0 13837 34.00 0.00 qemu-kvm
07:35:40 PM 0 13837 34.50 0.00 qemu-kvm
07:35:42 PM 0 13837 34.50 0.00 qemu-kvm
07:35:44 PM 0 13837 34.50 0.00 qemu-kvm
07:35:46 PM 0 13837 34.50 0.00 qemu-kvm
Average: 0 13837 34.40 0.00 qemu-kvm
[admin@kvm ~]$
Конфигурирование sar
Имя sar означает System Activity Reporter. В то время как такие инструменты, как vmstat, iotstat и pidstat используются для отображения статистики производительности в реальном времени, утилита sar использует процессы, которые собирают и хранят данные о производительности. В результате вы можете анализировать эти данные о производительности даже за период, который был в прошлом.
Чтобы использовать sar, нужно запустить два разных процесса. Если RPM-пакет sysstat установлен, это происходит автоматически через cron. Процессы sa1
и sa2 запускаются через /etc/cron.d/sysstat; в листинге 8 показана его конфигурация.
[admin@kvm cron.d]$ sudo cat sysstat
# Run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 1 1
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
# Generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A
[admin@kvm cron.d]$
Как видите, процесс sa1 собирает данные каждые 10 минут, а процесс sa2 делает это каждый день. Их можно настроить в соответствии с вашими потребностями.
Процессы sa собирают данные и записывают их в каталог /var/log/sa. Когда используется команда sar, она использует этот каталог для данных. По умолчанию данные производительности сохраняются за последние 28 дней, но это можно настроить с помощью переменной HISTORY, которая задается в файле /etc/sysconfig/sysstat.
Как только будет собрано достаточно данных, команда sar позволит вам получить информацию об этих данных.
Для фильтрации данных sar, которые были записаны между определенным временем, убедитесь, что используется военное время (military time), а не время, указанное как AM/PM. Распространенный способ сделать это - запустить sar с определением переменной LANG=C, как LANG=C sar -q. Чтобы убедиться, что sar всегда запускается таким образом, рекомендуется определить псевдоним в /etc/bashrc или ~/.bashrc:alias sar='LANG=C sar'
В упражнении ниже вы поработаете с sar, чтобы отобразить некоторые данные из журнала sar.
Упражнение. Использование sar для отображения информации об активности системы.
Зайдите под root. Введите команду, чтобы убедиться в правильности индикации времени в выводе sar: echo "alias sar='LANG=C sar'" >> /etc/bashrc
Откройте файл /etc/sysconfig/sysstat в редакторе и измените переменную HISTORY, чтобы сохранять историю в течение 60 дней. Убедитесь, что там написано HISTORY=60.
Посмотрите статистику сети, используя sar -n DEV.
Отобразите статистику I/O и информацию о скорости передачи, используя sar -b. Эта команда позволит вам определить пропускную способность I/O в течение более длительного периода времени.
Введите sar -P 0, чтобы показать статистику использования процессора.
Введите sar 1 10, чтобы отобразить вывод sar 10 раз с интервалом в 1 секунду.
Подводим итоги
В этой статье вы узнали о некоторых решениях для анализа производительности на сервере Linux. Вы узнали, как получить общий обзор параметров производительности, используя утилиту top. Затем вы узнали, как получить более подробную статистику производительности, используя различные инструменты из RPM-пакета sysstat и vmstat.
