Как автоматизировать репликацию и отказоустойчивость PostgreSQL 12 с помощью repmgr - часть 2
В первой части мы создали трехузловой кластер PostgreSQL 12 вместе с узлом-свидетелем. Кластер состоит из primary и двух standby узлов. Кластер и свидетель (PG-Node-Witness) размещены на KVM. Серверы, на которых размещены инстансы Postgres, размещены в одной сети:
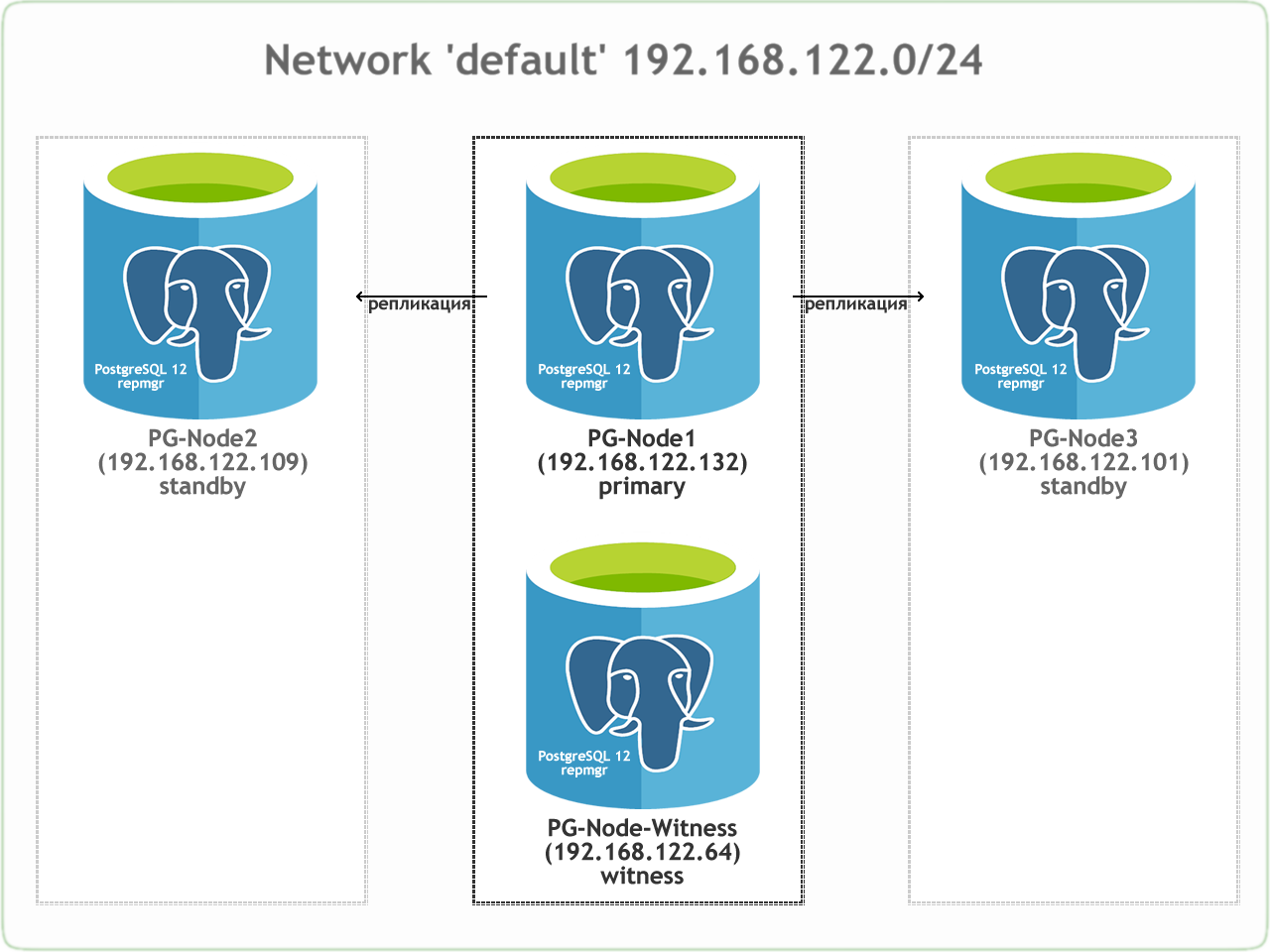
Также был установлен repmgr на primary и standby узлах и зарегистрирован primary узел. После этого мы клонировали оба standby узла из primary и запустили их. Оба standby узла также были зарегистрированы в repmgr. Команда "repmgr cluster show" показала нам, что все работает как и ожидалось:
Настроить потоковую репликацию с помощью repmgr очень просто. Далее нам нужно убедиться, что кластер будет функционировать даже тогда, когда основной станет недоступным. Это то, что мы и сделаем.
Для напоминания ниже показана детальная таблица узлов:
Например:
Есть два способа решить это:
Эта ситуация имеет некоторые дополнительные проблемы:
В первой части статьи мы развернули узел-свидетель. Мы назвали его PG-Node-Witness и установили там PostgreSQL 12. В этом посте мы также установим repmgr, но позже.
Вторым компонентом решения является демон repmgr (repmgrd), работающий на всех узлах кластера и узле-свидетеле. Опять же, мы не запустили этого демона в первой части статьи, но мы сделаем это здесь. Демон входит в состав пакета repmgr - при включении он работает как обычная служба и постоянно отслеживает состояние кластера. Он инициирует аварийное переключение при достижении кворума о том, что основной сервер находится в автономном режиме. Он не только может автоматически переходить в режим ожидания, но также может повторно инициировать другие резервы в кластере с несколькими узлами, чтобы следовать за новым первичным сервером.
И установим repmgr:
Затем добавим эти строки в postgresql.conf:
Там же (PG-Node-Witness) в файл pg_hba.conf добавим:
После внесения изменений в postgresql.conf и pg_hba.conf создадим пользователя-владельца repmgr и базу данных repmgr и изменим путь поиска по умолчанию для пользователя repmgr:
Наконец, добавим следующие строки в файл /etc/repmgr/12/repmgr.conf:
Перезапустим сервис:
Проверим, что PG-Node1 может подключиться к этому узлу-свидетелю:
Затем зарегистрируем PG-Node-Witness в repmgr, выполнив "repmgr witness register" под пользователем postgres. Обратите внимание, что используется адрес PG-Node1, а НЕ PG-Node-Witness:
Это связано с тем, что команда "repmgr witness register" добавляет метаданные узла-свидетеля в базу данных repmgr основного узла и, если необходимо, инициализирует узел-свидетель, устанавливая расширение repmgr и копируя метаданные repmgr на узел-свидетель.
Результат будет таким:
Проверяем состояние общей настройки с любого узла:
Когда кластер и узел-свидетель работают, мы добавляем следующие строки в файл sudoers в каждом узле кластера и узле-свидетеля:
failover
Параметр отработки отказа является одним из обязательных параметров для демона repmgr. Этот параметр сообщает демону, следует ли ему инициировать автоматическое аварийное переключение при обнаружении ситуации аварийного переключения. Может иметь одно из двух значений: "manual" или "automatic"
Установим его на automatic на каждом узле:
promote_command
Еще один обязательный параметр для демона repmgr. Этот параметр сообщает демону repmgr, какую команду он должен выполнить, чтобы активировать резервный узел. Значением этого параметра обычно будет команда "repmgr standby promote" или путь к сценарию оболочки, который вызывает команду.
Для нашего варианта использования мы устанавливаем следующее в каждом узле:
follow_command
Третий обязательный параметр для демона repmgr. Этот параметр указывает резервному узлу следовать за новым primary. Демон repmgr заменяет %n идентификатор узла нового primary сервера во время выполнения:
priority
Параметр priority добавляет вес к праву узла стать основным. Установка более высокого значения дает узлу большую возможность стать основным узлом. Кроме того, установка этого значения в ноль для узла будет гарантировать, что узел никогда не будет продвинут до основного.
В нашем случае использования у нас есть два резервных: PG-Node2 и PG-Node3. Мы хотим продвигать PG-Node2 как новый первичный, когда PG-Node1 переходит в автономный режим, а PG-Node3 следовать за PG-Node2.
Установим такие значения на резервных узлах:
monitor_interval_secs
Параметр сообщает демону repmgr, как часто (в секундах) он должен проверять доступность вышестоящего узла. В нашем случае существует только один вышестоящий узел: основной узел. Значение по умолчанию составляет 2 секунды, но мы явно устанавливим это значение на каждом узле:
connection_check_type
connection_check_type указывает, какой протокол будет использоваться для связи с вышестоящим узлом. Этот параметр может принимать три значения:
reconnect_attempts и reconnect_interval
Когда первичный сервер становится недоступным, демон repmgr на резервных узлах будет пытаться переподключиться к первичному серверу reconnect_attempts раз. Значение по умолчанию для этого параметра - 6. Между каждой попыткой переподключения он будет ждать reconnect_interval секунд, значение по умолчанию которого равно 10. В демонстрационных целях мы будем использовать короткий интервал и меньшее количество попыток переподключения.
Установим эти значения на каждом узле:
primary_visibility_consensus
Когда первичный сервер становится недоступным в многоузловом кластере, резервные узлы могут консультироваться друг с другом, чтобы создать кворум для отработки отказа, спрашивая каждый резервный узел о времени, когда он в последний раз видел основной узел. Если последняя связь с узлом была недавней и позже времени, когда этот узел увидел первичный узел, локальный узел предполагает, что первичный узел все еще доступен, и не принимает решение об отказоустойчивости.
Чтобы включить эту модель консенсуса, параметр primary_visibility_consensus должен быть установлен как "true" на каждом узле, включая свидетеля (PG-Node-Witness):
standby_disconnect_on_failover
Когда для параметра standby_disconnect_on_failover на резервном узле задано значение "true", демон repmgr будет гарантировать, что его приемник WAL отключен от основного и не получает сегменты WAL. Он также будет ждать, пока приемники WAL других резервных узлов прекратят работу, прежде чем принимать решение об отказоустойчивости.
Для этого параметра должно быть установлено одинаковое значение на каждом узле.
true означает, что каждый резервный узел прекратил получать данные с первичного сервера при сбое. Процесс будет иметь задержку в 5 секунд плюс время, необходимое приемнику WAL для остановки перед принятием решения об отказоустойчивости. По умолчанию демон repmgr будет ждать 30 секунд, чтобы подтвердить, что все узлы-братья перестали получать сегменты WAL, прежде чем произойдет аварийное переключение.
repmgrd_service_start_command и repmgrd_service_stop_command
Эти два параметра определяют, как запускать и останавливать демон repmgr с помощью команд "repmgr daemon start" и "repmgr daemon stop".
По сути, эти две команды являются оболочками команд ОС для запуска/остановки службы. Два значения параметров сопоставляют эти команды их версиям для конкретной ОС.
Установим эти параметры на каждом узле:
monitoring_history
Если для параметра monitor_history задано значение "yes", repmgr сохраняет свои данные мониторинга кластера.
Установим "yes" на каждом узле:
log_status_interval
Мы устанавливаем параметр на каждом узле, чтобы указать, как часто демон repmgr будет регистрировать сообщение о состоянии.
Установим регистрацию каждые 60 секунд:
Команда должна быть выполнена от имени postgres:
Вывод должен быть таким:
Далее запускаем демон на всех четырех узлах:
Выходные данные в каждом узле должны показать, что демон запущен:
Также проверим событие запуска службы с основного или резервного узлов:
Вывод должен показать, что демон контролирует соединения:
И наконец, проверим вывод демона из системного журнала на любом резервном узле:
Вот вывод из PG-Node3:
Проверка системного журнала на основном узле показывает другой вывод:
Здесь много информации, но давайте разберемся, как разворачивались события. Для простоты понимания сообщения сгрупированыи и между ними стоят пробелы.
Первый набор сообщений показывает, что демон repmgr пытается подключиться к первичному узлу (ID 1) четыре раза, используя PQPing(). Это связано с тем, что мы указали параметр connection_check_type для "ping" в файле repmgr.conf. После 4 попыток демон сообщает, что не может подключиться к основному узлу.
Следующий набор сообщений говорит нам, что резервные узлы отключили свои приемники WAL. Это потому, что мы установили для параметра standby_disconnect_on_failover значение "true" в файле repmgr.conf.
В следующем наборе сообщений резервные узлы и свидетель запрашивают информацию о последнем полученном LSN от основного узла и последнем LSN, когда основной был доступен. Последние полученные номера LSN совпадают на обоих резервных узлах. Узлы соглашаются, что они не видят первичный в течение последних 4 секунд. Обратите внимание, что демон repmgr также обнаруживает, что PG-Node3 имеет более низкий приоритет для продвижения. Поскольку ни один из узлов не видел первичного сервера в последнее время, они могут достичь кворума, что первичный не работает.
После этого у нас появляются сообщения о том, что repmgr выбирает PG-Node2 в качестве кандидата на повышение. Он объявляет победителя узла и говорит, что узел будет продвигать себя и информировать другие узлы.
Группа сообщений после этого показывает, что PG-Node2 успешно выдвигается на главную роль. Как только это будет сделано, узлам PG-Node3 (ID 3) и PG-Node-Witness (ID 4) сообщается о том, что они следуют за недавно повышенным основным.
Последний набор сообщений показывает, что два узла подключились к новому первичному серверу, и демон repmgr начал мониторинг локального узла.
Наш кластер вернулся в действие. Мы можем убедиться в этом, выполнив "repmgr cluster show":
Вывод, показанный ниже, не требует пояснений:
Мы также можем посмотреть события:
Вывод отображает, как это произошло:
Одна вещь, которая здесь не рассмотрена, - это "отгородить" вышедший из строя основной узел. В случае отработки отказа неисправный первичный сервер должен быть удален из кластера и оставаться недоступным для клиентских подключений. Это сделано для того, чтобы предотвратить любую ситуацию типа "split-brain" в случае, если старый первичный случайно вернется в онлайн. Демон repmgr может работать с инструментом пула соединений, таким как pgbouncer, для реализации процесса выделения. Более подробно об этом в документации 2ndQuadrant Github.
Кроме того, после отработки отказа приложениям, подключающимся к кластеру, необходимо изменить адрес подключения на новый основной узел. Это большая тема сама по себе, но одним из способов решения этой проблемы может быть использование виртуального IP-адреса (и связанного с ним разрешения DNS) для скрытия основного узла кластера.
Как автоматизировать репликацию и отказоустойчивость PostgreSQL 12 с помощью repmgr - часть 1
Также был установлен repmgr на primary и standby узлах и зарегистрирован primary узел. После этого мы клонировали оба standby узла из primary и запустили их. Оба standby узла также были зарегистрированы в repmgr. Команда "repmgr cluster show" показала нам, что все работает как и ожидалось:
Для напоминания ниже показана детальная таблица узлов:
| Узел | IP адрес | Роль | Приложения |
| PG-Node1 | 192.168.122.132 | Primary | PostgreSQL 12 и repmgr |
| PG-Node2 | 192.168.122.109 | Standby 1 | PostgreSQL 12 и repmgr |
| PG-Node3 | 192.168.122.101 | Standby 2 | PostgreSQL 12 и repmgr |
| PG-Node-Witness | 192.168.122.64 | Witness | PostgreSQL 12 и repmgr |
Возможная проблема
В репликации PostgreSQL первичный сервер может стать недоступным по нескольким причинам.Например:
- ОС основного узла может дать сбой или перестать отвечать на запросы.
- Сбой сети на основном узле.
- Служба PostgreSQL на основном узле может неожиданно завершить работу, остановиться или стать недоступной.
- Служба PostgreSQL на основном узле может быть остановлена намеренно или случайно.
Есть два способа решить это:
- Резервный сервер вручную обновляется до основной роли.
- Резервный сервер автоматически повышается до основной роли. Это относится к сторонним инструментам, которые непрерывно отслеживают репликацию и выполняют действия по восстановлению, когда основной недоступен. Repmgr является одним из таких инструментов.
Эта ситуация имеет некоторые дополнительные проблемы:
- Если существует более одного резервного узла, как repmgr решает, какой из них следует продвигать в качестве основного? Как работает кворум и процесс продвижения?
- Если один из них сделан первичным, то как другие узлы начинают "следовать за ним" как за первичным?
- Что произойдет, если основной функционирует, но по какой-то причине временно отключен от сети? Если один из резервных узлов становится первичным, а затем первоначальный первичный возвращается в рабочий режим, как можно избежать ситуации с принципом "split brain"?
Узел PG-Node-Witness и демон repmgr
Чтобы ответить на эти вопросы, repmgr использует нечто, называемое узлом-свидетелем. Когда основной недоступен - задача узла-свидетеля состоит в том, чтобы помочь резервным узлам достичь кворума, если один из них будет повышен до основной роли. Резервные узлы достигают этого кворума, определяя, действительно ли основной узел находится в автономном режиме или только временно недоступен. Узел-свидетель должен находиться в том же датацентре / сегменте сети / подсети, что и основной узел, но НИКОГДА не должен работать на том же физическом хосте, что и основной узел.В первой части статьи мы развернули узел-свидетель. Мы назвали его PG-Node-Witness и установили там PostgreSQL 12. В этом посте мы также установим repmgr, но позже.
Вторым компонентом решения является демон repmgr (repmgrd), работающий на всех узлах кластера и узле-свидетеле. Опять же, мы не запустили этого демона в первой части статьи, но мы сделаем это здесь. Демон входит в состав пакета repmgr - при включении он работает как обычная служба и постоянно отслеживает состояние кластера. Он инициирует аварийное переключение при достижении кворума о том, что основной сервер находится в автономном режиме. Он не только может автоматически переходить в режим ожидания, но также может повторно инициировать другие резервы в кластере с несколькими узлами, чтобы следовать за новым первичным сервером.
Процесс кворума
Когда резервные узлы понимают, что не видят основной, они начинают консультироваться между собой. Все резервные сервера, работающие в кластере, достигают кворума, чтобы выбрать новый первичный сервер, используя серию проверок:- Каждый раз резервный сервер опрашивает других, когда они последний раз "видели" основной сервер. Если последний реплицированный LSN в режиме ожидания или время последней связи с первичным сервером более позднее, чем последний реплицированный LSN текущего узла или во время последней связи узел ничего не делает и ожидает восстановления связи с первичным сервером.
- Если ни один из резервных серверов не видит основной сервер, они проверяют, доступен ли узел-свидетель. Если к узлу-свидетелю также не удается подключиться, резервные серверы предполагают, что на первичном сервере произошел сбой сети, и перестают выбирать новый.
- Если узел-свидетель доступен, резервные узлы предполагают, что основной сервер не работает, и приступают к выборам кто из них станет основным.
- Узел, который был настроен как "предпочтительный" основной, будет повышен до роли primary. Каждой резервный узел повторно инициализирует репликацию с новому primary узлом.
Настройка кластера на автоматизацию отказоустойчивости
Теперь мы настроим кластер и узел-свидетель для автоматизации отказоустойчивости.Шаг 1: Установка и настройка repmgr на PG-Node-Witness
Добавим репозитрий:# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpmИ установим repmgr:
# yum install repmgr12 –yЗатем добавим эти строки в postgresql.conf:
listen_addresses = '*'
shared_preload_libraries = 'repmgr'Там же (PG-Node-Witness) в файл pg_hba.conf добавим:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.122.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.122.0/24 trustПосле внесения изменений в postgresql.conf и pg_hba.conf создадим пользователя-владельца repmgr и базу данных repmgr и изменим путь поиска по умолчанию для пользователя repmgr:
[postgres@PG-Node-Witness ~]$ createuser --superuser repmgr
[postgres@PG-Node-Witness ~]$ createdb --owner=repmgr repmgr
[postgres@PG-Node-Witness ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"Наконец, добавим следующие строки в файл /etc/repmgr/12/repmgr.conf:
node_id=4
node_name='PG-Node-Witness'
conninfo='host=192.168.122.64 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/var/lib/pgsql/12/data'Перезапустим сервис:
# systemctl restart postgresql-12.serviceПроверим, что PG-Node1 может подключиться к этому узлу-свидетелю:
[postgres@PG-Node1 ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'Затем зарегистрируем PG-Node-Witness в repmgr, выполнив "repmgr witness register" под пользователем postgres. Обратите внимание, что используется адрес PG-Node1, а НЕ PG-Node-Witness:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 192.168.122.132Это связано с тем, что команда "repmgr witness register" добавляет метаданные узла-свидетеля в базу данных repmgr основного узла и, если необходимо, инициализирует узел-свидетель, устанавливая расширение repmgr и копируя метаданные repmgr на узел-свидетель.
Результат будет таким:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4)
INFO: connecting to primary node
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
INFO: witness registration complete
NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registeredПроверяем состояние общей настройки с любого узла:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact Шаг 2: Изменение файла sudoers
Шаг 2: Изменение файла sudoers
Когда кластер и узел-свидетель работают, мы добавляем следующие строки в файл sudoers в каждом узле кластера и узле-свидетеля:Defaults:postgres !requiretty
postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.serviceШаг 3: Настройка параметров repmgrd
На каждом узле мы уже добавили четыре параметра в файл repmgr.conf. Добавленные параметры являются основными, необходимыми для работы repmgr. Чтобы включить демон repmgr и автоматический переход на другой ресурс, необходимо включить / добавить ряд других параметров. В следующих подразделах я опишу каждый параметр и значение, которое они будут устанавливать на каждом узле.failover
Параметр отработки отказа является одним из обязательных параметров для демона repmgr. Этот параметр сообщает демону, следует ли ему инициировать автоматическое аварийное переключение при обнаружении ситуации аварийного переключения. Может иметь одно из двух значений: "manual" или "automatic"
Установим его на automatic на каждом узле:
failover='automatic'promote_command
Еще один обязательный параметр для демона repmgr. Этот параметр сообщает демону repmgr, какую команду он должен выполнить, чтобы активировать резервный узел. Значением этого параметра обычно будет команда "repmgr standby promote" или путь к сценарию оболочки, который вызывает команду.
Для нашего варианта использования мы устанавливаем следующее в каждом узле:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'follow_command
Третий обязательный параметр для демона repmgr. Этот параметр указывает резервному узлу следовать за новым primary. Демон repmgr заменяет %n идентификатор узла нового primary сервера во время выполнения:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'priority
Параметр priority добавляет вес к праву узла стать основным. Установка более высокого значения дает узлу большую возможность стать основным узлом. Кроме того, установка этого значения в ноль для узла будет гарантировать, что узел никогда не будет продвинут до основного.
В нашем случае использования у нас есть два резервных: PG-Node2 и PG-Node3. Мы хотим продвигать PG-Node2 как новый первичный, когда PG-Node1 переходит в автономный режим, а PG-Node3 следовать за PG-Node2.
Установим такие значения на резервных узлах:
Узел | Значение |
PG-Node2 | priority=60 |
PG-Node3 | priority=40 |
monitor_interval_secs
Параметр сообщает демону repmgr, как часто (в секундах) он должен проверять доступность вышестоящего узла. В нашем случае существует только один вышестоящий узел: основной узел. Значение по умолчанию составляет 2 секунды, но мы явно устанавливим это значение на каждом узле:
monitor_interval_secs = 2connection_check_type
connection_check_type указывает, какой протокол будет использоваться для связи с вышестоящим узлом. Этот параметр может принимать три значения:
- ping: repmgr использует метод PQPing().
- connection: repmgr пытается создать новое соединение с вышестоящим узлом.
- query: repmgr пытается выполнить SQL-запрос на вышестоящем узле, используя существующее соединение.
connection_check_type = 'ping'reconnect_attempts и reconnect_interval
Когда первичный сервер становится недоступным, демон repmgr на резервных узлах будет пытаться переподключиться к первичному серверу reconnect_attempts раз. Значение по умолчанию для этого параметра - 6. Между каждой попыткой переподключения он будет ждать reconnect_interval секунд, значение по умолчанию которого равно 10. В демонстрационных целях мы будем использовать короткий интервал и меньшее количество попыток переподключения.
Установим эти значения на каждом узле:
reconnect_attempts = 4
reconnect_interval = 8primary_visibility_consensus
Когда первичный сервер становится недоступным в многоузловом кластере, резервные узлы могут консультироваться друг с другом, чтобы создать кворум для отработки отказа, спрашивая каждый резервный узел о времени, когда он в последний раз видел основной узел. Если последняя связь с узлом была недавней и позже времени, когда этот узел увидел первичный узел, локальный узел предполагает, что первичный узел все еще доступен, и не принимает решение об отказоустойчивости.
Чтобы включить эту модель консенсуса, параметр primary_visibility_consensus должен быть установлен как "true" на каждом узле, включая свидетеля (PG-Node-Witness):
primary_visibility_consensus = truestandby_disconnect_on_failover
Когда для параметра standby_disconnect_on_failover на резервном узле задано значение "true", демон repmgr будет гарантировать, что его приемник WAL отключен от основного и не получает сегменты WAL. Он также будет ждать, пока приемники WAL других резервных узлов прекратят работу, прежде чем принимать решение об отказоустойчивости.
Для этого параметра должно быть установлено одинаковое значение на каждом узле.
standby_disconnect_on_failover = truetrue означает, что каждый резервный узел прекратил получать данные с первичного сервера при сбое. Процесс будет иметь задержку в 5 секунд плюс время, необходимое приемнику WAL для остановки перед принятием решения об отказоустойчивости. По умолчанию демон repmgr будет ждать 30 секунд, чтобы подтвердить, что все узлы-братья перестали получать сегменты WAL, прежде чем произойдет аварийное переключение.
repmgrd_service_start_command и repmgrd_service_stop_command
Эти два параметра определяют, как запускать и останавливать демон repmgr с помощью команд "repmgr daemon start" и "repmgr daemon stop".
По сути, эти две команды являются оболочками команд ОС для запуска/остановки службы. Два значения параметров сопоставляют эти команды их версиям для конкретной ОС.
Установим эти параметры на каждом узле:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service'
repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'Команды Start/Stop/Restart службы PostgreSQL
В рамках своей работы демон repmgr часто должен останавливать, запускать или перезапускать службу PostgreSQL. Чтобы это происходило гладко, лучше всего указать соответствующие команды операционной системы в качестве значений параметров в файле repmgr.conf. Для этого на каждом узле установим четыре параметра:service_start_command='sudo /usr/bin/systemctl start postgresql-12.service'
service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service'
service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service'
service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'monitoring_history
Если для параметра monitor_history задано значение "yes", repmgr сохраняет свои данные мониторинга кластера.
Установим "yes" на каждом узле:
monitoring_history=yeslog_status_interval
Мы устанавливаем параметр на каждом узле, чтобы указать, как часто демон repmgr будет регистрировать сообщение о состоянии.
Установим регистрацию каждые 60 секунд:
log_status_interval=60Шаг 4. Запуск демона repmgr
Теперь, когда параметры установлены в кластере и на узле-свидетеле, выполним пробный запуск команды, чтобы запустить демон repmgr. Сначала проверяем это на основном узле, а затем на двух резервных узлах, а затем на узле-свидетеле.Команда должна быть выполнена от имени postgres:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-runВывод должен быть таким:
INFO: prerequisites for starting repmgrd met
DETAIL: following command would be executed:
sudo /usr/bin/systemctl start repmgr12.serviceДалее запускаем демон на всех четырех узлах:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon startВыходные данные в каждом узле должны показать, что демон запущен:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service"
NOTICE: repmgrd was successfully startedТакже проверим событие запуска службы с основного или резервного узлов:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_startВывод должен показать, что демон контролирует соединения:
Node ID | Name | Event | OK | Timestamp | Details
--------+-----------------+---------------+----+---------------------+------------------------------------------------------------------
4 | PG-Node-Witness | repmgrd_start | t | 2020-03-10 20:27:10 | witness monitoring connection to primary node "PG-Node1" (ID: 1)
3 | PG-Node3 | repmgrd_start | t | 2020-03-10 20:27:37 | monitoring connection to upstream node "PG-Node1" (ID: 1)
2 | PG-Node2 | repmgrd_start | t | 2020-03-10 20:27:24 | monitoring connection to upstream node "PG-Node1" (ID: 1)
1 | PG-Node1 | repmgrd_start | t | 2020-03-10 20:23:54 | monitoring cluster primary "PG-Node1" (ID: 1)И наконец, проверим вывод демона из системного журнала на любом резервном узле:
# cat /var/log/messages | grep repmgr | lessВот вывод из PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf"
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"
Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3)
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping"
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1)
Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state
Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago
Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal stateПроверка системного журнала на основном узле показывает другой вывод:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf"
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1)
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping"
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1)
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached
Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected
Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state
Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state
…
…Шаг 5: Имитация сбоя PG-Node1
Теперь мы смоделируем неисправность первичного узла, остановив его. На этом узле запустим команду:# systemctl stop postgresql-12.serviceПроцесс отработки отказа
Как только процесс останавливается, мы ждем около минуты или двух, а затем проверяем файл системного журнала PG-Node2.Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds
…
…
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes
…
…
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote()
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2)
Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected
Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected
Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected
Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state
Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state
…
…Здесь много информации, но давайте разберемся, как разворачивались события. Для простоты понимания сообщения сгрупированыи и между ними стоят пробелы.
Первый набор сообщений показывает, что демон repmgr пытается подключиться к первичному узлу (ID 1) четыре раза, используя PQPing(). Это связано с тем, что мы указали параметр connection_check_type для "ping" в файле repmgr.conf. После 4 попыток демон сообщает, что не может подключиться к основному узлу.
Следующий набор сообщений говорит нам, что резервные узлы отключили свои приемники WAL. Это потому, что мы установили для параметра standby_disconnect_on_failover значение "true" в файле repmgr.conf.
В следующем наборе сообщений резервные узлы и свидетель запрашивают информацию о последнем полученном LSN от основного узла и последнем LSN, когда основной был доступен. Последние полученные номера LSN совпадают на обоих резервных узлах. Узлы соглашаются, что они не видят первичный в течение последних 4 секунд. Обратите внимание, что демон repmgr также обнаруживает, что PG-Node3 имеет более низкий приоритет для продвижения. Поскольку ни один из узлов не видел первичного сервера в последнее время, они могут достичь кворума, что первичный не работает.
После этого у нас появляются сообщения о том, что repmgr выбирает PG-Node2 в качестве кандидата на повышение. Он объявляет победителя узла и говорит, что узел будет продвигать себя и информировать другие узлы.
Группа сообщений после этого показывает, что PG-Node2 успешно выдвигается на главную роль. Как только это будет сделано, узлам PG-Node3 (ID 3) и PG-Node-Witness (ID 4) сообщается о том, что они следуют за недавно повышенным основным.
Последний набор сообщений показывает, что два узла подключились к новому первичному серверу, и демон repmgr начал мониторинг локального узла.
Наш кластер вернулся в действие. Мы можем убедиться в этом, выполнив "repmgr cluster show":
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compactВывод, показанный ниже, не требует пояснений:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
ID | Name | Role | Status | Upstream | Location | Prio. | TLI
----+-----------------+---------+-----------+----------+----------+-------+-----
1 | PG-Node1 | primary | ! running | | default | 100 | 1
2 | PG-Node2 | primary | * running | | default | 100 | 2
3 | PG-Node3 | standby | running | PG-Node2 | default | 100 | 2
4 | PG-Node-Witness | witness | * running | PG-Node2 | default | 0 | 1
WARNING: following issues were detected
- node "PG-Node1" (ID: 1) is running but the repmgr node record is inactiveМы также можем посмотреть события:
[postgres@PG-Node2 ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster eventВывод отображает, как это произошло:
[postgres@PG-Node2 ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
Node ID | Name | Event | OK | Timestamp | Details
---------+-----------------+----------------------------+----+---------------------+-----------------------------------------------------------------------------------------
2 | PG-Node2 | child_node_new_connect | t | 2020-03-10 20:33:18 | new standby "PG-Node3" (ID: 3) has connected
3 | PG-Node3 | repmgrd_failover_follow | t | 2020-03-10 20:33:14 | node 3 now following new upstream node 2
3 | PG-Node3 | standby_follow | t | 2020-03-10 20:33:14 | standby attached to upstream node "PG-Node2" (ID: 2)
2 | PG-Node2 | child_node_new_connect | t | 2020-03-10 20:33:12 | new witness "PG-Node-Witness" (ID: 4) has connected
4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-03-10 20:33:06 | witness monitoring connection to primary node "PG-Node2" (ID: 2)
4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-03-10 20:33:06 | witness node 4 now following new primary node 2
2 | PG-Node2 | repmgrd_reload | t | 2020-03-10 20:33:06 | monitoring cluster primary "PG-Node2" (ID: 2)
2 | PG-Node2 | repmgrd_failover_promote | t | 2020-03-10 20:33:06 | node 2 promoted to primary; old primary 1 marked as failed
2 | PG-Node2 | standby_promote | t | 2020-03-10 20:33:06 | server "PG-Node2" (ID: 2) was successfully promoted to primary
3 | PG-Node3 | repmgrd_start | t | 2020-03-10 20:27:37 | monitoring connection to upstream node "PG-Node1" (ID: 1)
2 | PG-Node2 | repmgrd_start | t | 2020-03-10 20:27:24 | monitoring connection to upstream node "PG-Node1" (ID: 1)
1 | PG-Node1 | child_node_new_connect | t | 2020-03-10 20:27:10 | new witness "PG-Node-Witness" (ID: 4) has connected
4 | PG-Node-Witness | repmgrd_start | t | 2020-03-10 20:27:10 | witness monitoring connection to primary node "PG-Node1" (ID: 1)
1 | PG-Node1 | repmgrd_start | t | 2020-03-10 20:23:54 | monitoring cluster primary "PG-Node1" (ID: 1)
4 | PG-Node-Witness | witness_register | t | 2020-03-10 03:15:48 | witness registration succeeded; upstream node ID is 1
3 | PG-Node3 | standby_register | t | 2020-03-10 03:05:39 | standby registration succeeded; upstream node ID is 1
3 | PG-Node3 | standby_clone | t | 2020-03-10 03:05:11 | cloned from host "192.168.122.132", port 5432; backup method: pg_basebackup; --force: N
2 | PG-Node2 | standby_register | t | 2020-03-10 03:03:40 | standby registration succeeded; upstream node ID is 1
2 | PG-Node2 | standby_clone | t | 2020-03-10 03:02:30 | cloned from host "192.168.122.132", port 5432; backup method: pg_basebackup; --force: N
3 | PG-Node3 | standby_unregister | t | 2020-03-10 02:56:28 |Заключение
Вот и всё. Как мы видели в первой части, настройка многоузловой репликации PostgreSQL очень проста с repmgr. Демон делает еще проще - автоматизирует отработку отказа. Он также автоматически перенаправляет существующие резервные узлы, чтобы следовать новому основному. В нативной репликации PostgreSQL все существующие резервные системы должны быть настроены вручную для репликации с нового основного сервера - автоматизация этого процесса экономит драгоценное время и усилия.Одна вещь, которая здесь не рассмотрена, - это "отгородить" вышедший из строя основной узел. В случае отработки отказа неисправный первичный сервер должен быть удален из кластера и оставаться недоступным для клиентских подключений. Это сделано для того, чтобы предотвратить любую ситуацию типа "split-brain" в случае, если старый первичный случайно вернется в онлайн. Демон repmgr может работать с инструментом пула соединений, таким как pgbouncer, для реализации процесса выделения. Более подробно об этом в документации 2ndQuadrant Github.
Кроме того, после отработки отказа приложениям, подключающимся к кластеру, необходимо изменить адрес подключения на новый основной узел. Это большая тема сама по себе, но одним из способов решения этой проблемы может быть использование виртуального IP-адреса (и связанного с ним разрешения DNS) для скрытия основного узла кластера.
Как автоматизировать репликацию и отказоустойчивость PostgreSQL 12 с помощью repmgr - часть 1
